 EN
EN

MCCX D800 – AI 大模型训推一体机



大语言模型训练 / 微调
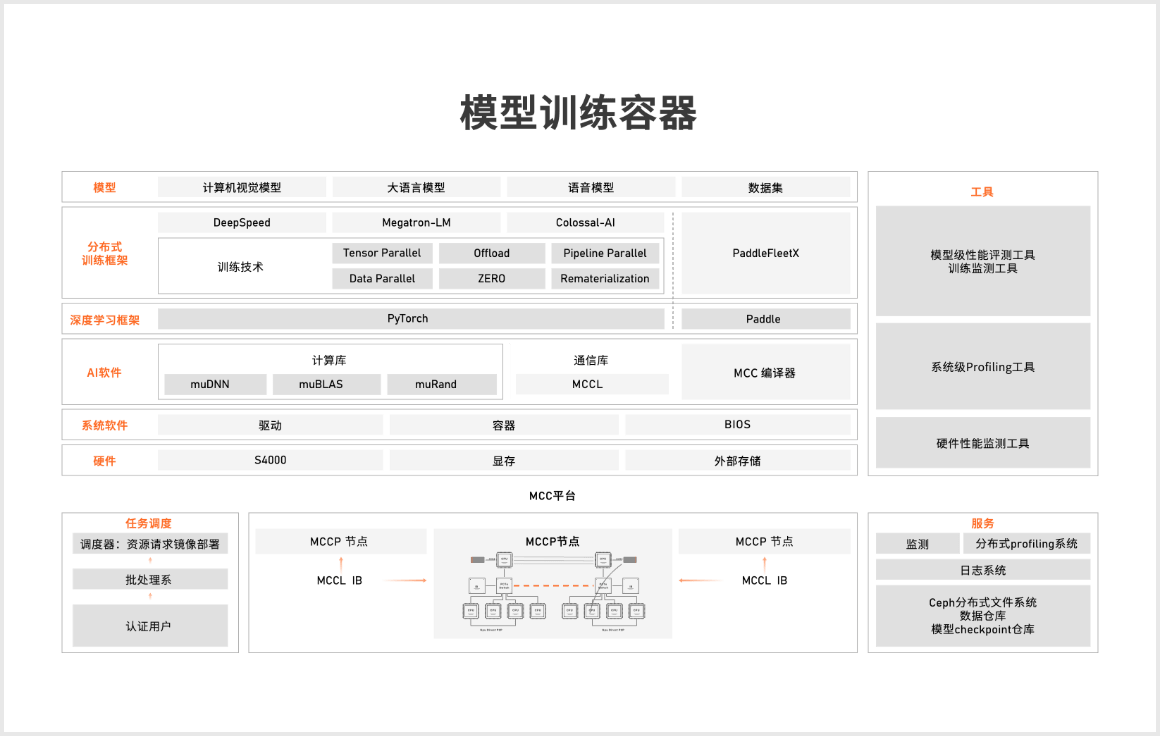
大模型训练平台架构
摩尔线程大模型训练平台,完全兼容 CUDA 和 Pytorch 训练系统,支持 Megatron-LM、DeepSpeed、FSDP 和 Colossal-AI 等大模型分布式训练框架。具有全兼容、高性能、高灵活性和简单易用等特点。支持 GPT 系列、LLaMA 系列、GLM 系列等常见大模型的一键千卡训练。使用夸娥千卡智算集群进行大模型训练,线性加速比可达91%以上。支持 Pytorch 用户自主研发,支持模型训练全监控、自动拉起、断点续训等功能。
大模型训练 / 微调实例
MTT S4000 配备的 Tensor 核心算力、48GB 显存以及超高速卡间互连接口 MTLink,可以有效支持多种主流大语言模型训练,包括: LLaMA / GPT / ChatGLM / Qwen / Baichuan 等。 通过摩尔线程大模型训练平台,支持单机 8 卡和多机多卡等多种分布式训练策略,加速从 60 亿参数到千亿参数大语言模型训练以及微调任务。
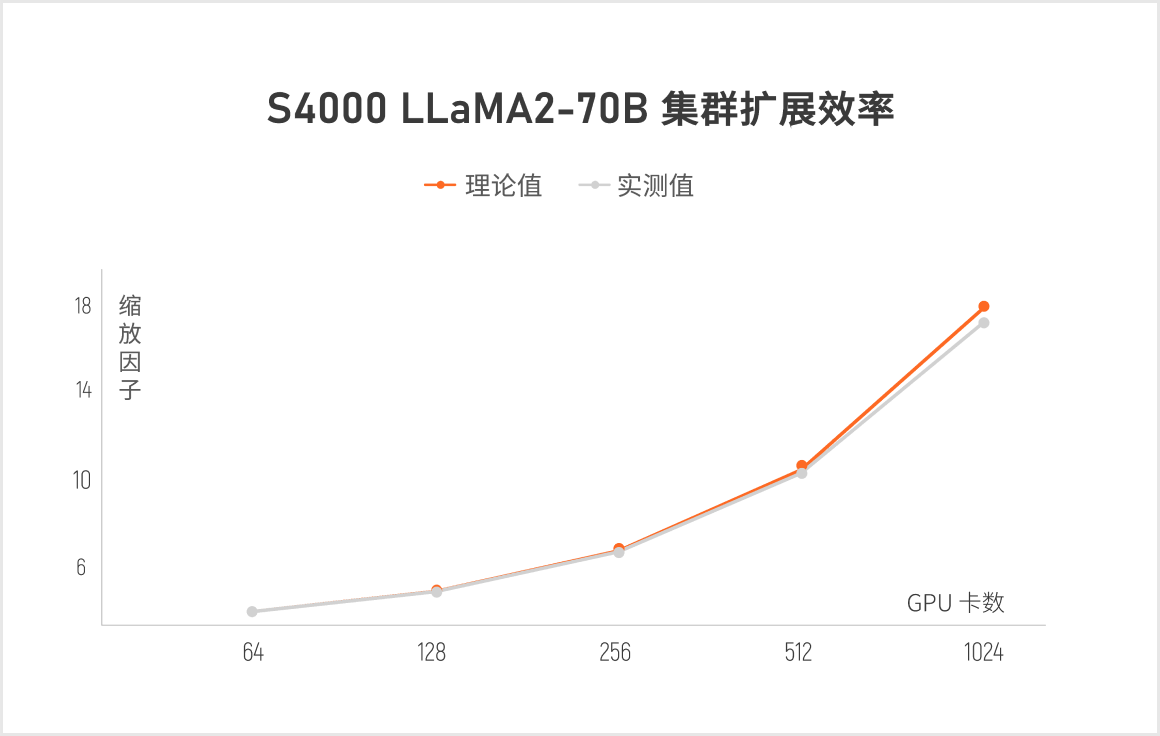
集群扩展效率
摩尔线程 KUAE 千卡模型训练平台,支持千亿参数模型的预训练、微调和推理,可实现 91% 的千卡集群线性加速比,摩尔线程从应用、分布式系统、训练框架、通讯库、固件、算子、硬件全方位进行优化。MTLink 是基于 MTT S4000 自研的卡间互连技术,支持 2 卡、4卡、8 卡 MTLink Bridge 互连,提升了卡间互连带宽,卡间互连 I/O 带宽达到 240GB/s,可加速集群从 64 卡到 1024 卡的训练速度以及多卡互连的线性度。
大模型推理服务平台
MTT S4000 配备的 Tensor 核心算力以及 48GB 显存,可以有效支持主流大语言模型推理,包括:LLaMA / ChatGLM / Qwen / Baichuan 等主流系列大模型。
KUAE ModelStudio
是面向大语言模型应用场景开发者,基于摩尔线程 GPU 以及官方提供的模型,进行训练、微调和推理的一体化应用平台。
MUSA Serving
是摩尔线程提供的一套推理服务软件,可提供高性能、分布式的推理服务,支持 LLM、图片/视频生成模型、传统 AI 模型等后端模型部署。
MT Transformer
是一套针对摩尔线程 GPU 的分布式推理加速框架,实现了对基于 Transformer 架构 LLM 模型的推理加速。
TensorX
是一套针对摩尔线程 GPU 的推理加速框架,实现了对图片/视频生成、传统 AI 模型的推理加速。
从芯片到集群,加速国产算力规模化供给能力
完美支持 KUAE 集群产品系列
为大模型训练集群,优化的服务器硬件系统,出色支持摩尔线程智算中心全栈解决方案 KUAE K1/K2/K3


全面支持 KUAE 智算中心软件栈全特性
MCCX D800 不仅仅支持大模型
MCCX D800
产品规格
FP32 200TFLOPS
FP16 800TFLOPS
数据盘:4*3.84T PCIe Gen4 NVMe SSD
2 * 2 端口 25Gb 光接口网卡





