 EN
EN


摩尔线程大模型智算加速卡 MTT S4000,采用第三代 MUSA 架构,配备了 Tensor 核心,单卡支持 48GB 显存和 768GB/s 的显存带宽。基于摩尔线程自研 MTLink 技术,MTT S4000 可以支持多卡互联,支持千卡集群基础设施建设,加速千亿参数大语言模型计算。同时,MTT S4000 提供先进的图形渲染能力、视频编解码能力和超高清 8K HDR 显示能力,助力 AI 计算、图形渲染、多媒体等综合应用场景的落地。尤为重要的是,基于摩尔线程自研的全功能 GPU MUSA 生态架构,MTT S4000 可以充分兼容现有软件生态,实现代码零成本迁移到 MUSA 平台。






大语言模型训练 / 微调
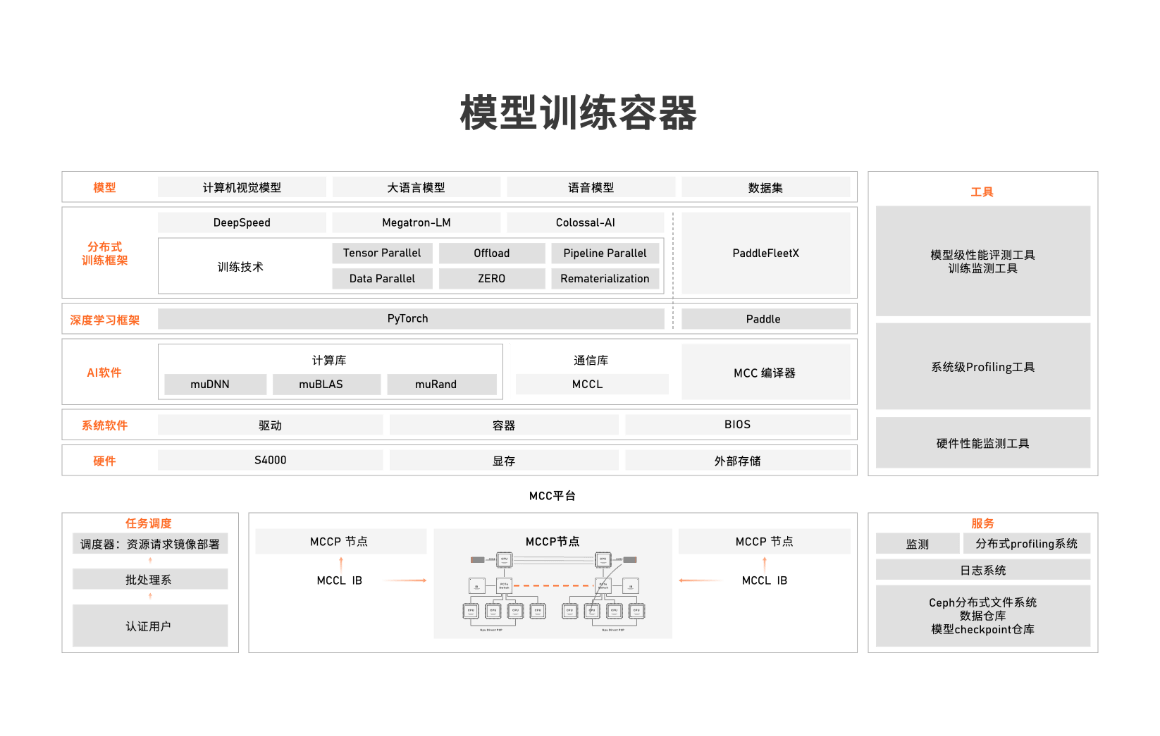
大模型训练平台架构

大模型训练 / 微调实例
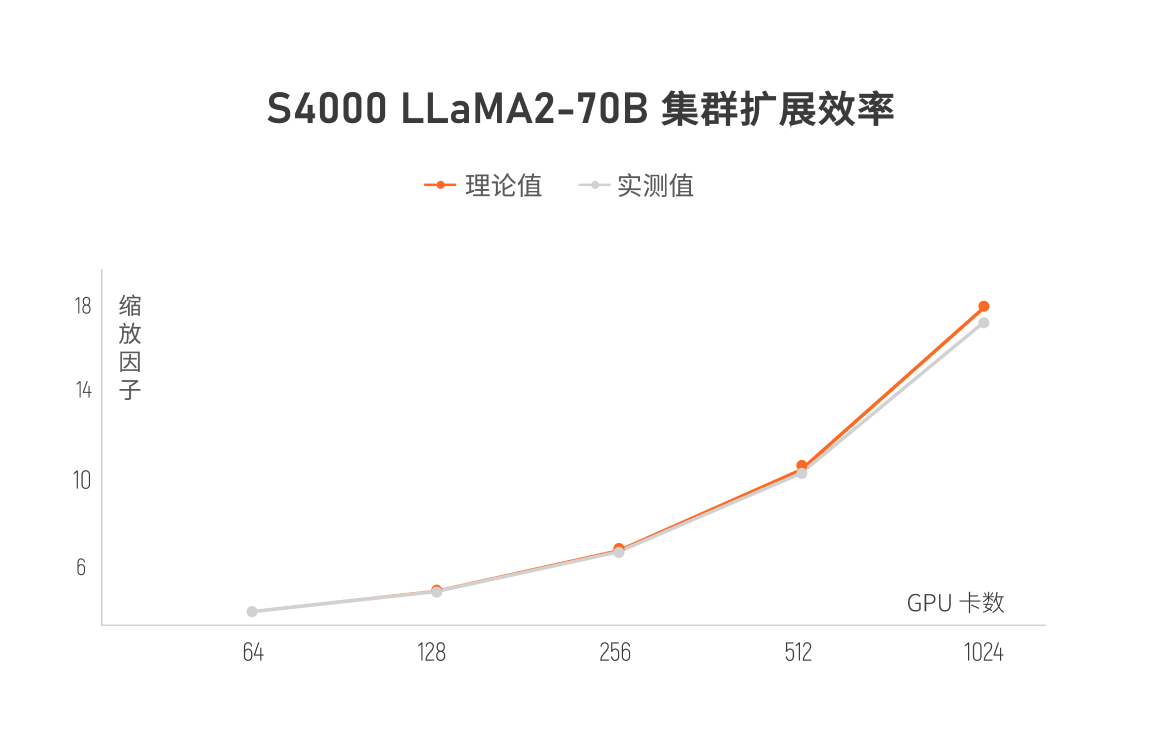
集群扩展效率
大模型推理服务平台
MTT S4000 配备的 Tensor 核心算力以及 48GB 显存,可以有效支持主流大语言模型推理,包括:LLaMA / ChatGLM / Qwen / Baichuan 等主流系列大模型。
KUAE ModelStudio
是面向大语言模型应用场景开发者,基于摩尔线程 GPU 以及官方提供的模型,进行训练、微调和推理的一体化应用平台。
MUSA Serving
是摩尔线程提供的一套推理服务软件,可提供高性能、分布式的推理服务,支持 LLM、图片/视频生成模型、传统 AI 模型等后端模型部署。
MT Transformer
是一套针对摩尔线程 GPU 的分布式推理加速框架,实现了对基于 Transformer 架构 LLM 模型的推理加速。
TensorX
是一套针对摩尔线程 GPU 的推理加速框架,实现了对图片/视频生成、传统 AI 模型的推理加速。
支持 KUAE 集群产品
MTT KUAE 是摩尔线程智算中心全栈解决方案,基于 MTT S4000 和双路 8 卡 GPU 服务器 MCCX D800 X1,以一体化交付的方式解决大规模 GPU 算力的建设和运营管理问题。


新一代 Tensor 核心
摩尔线程新一代 Tensor Core,助力大语言模型的训练、微调和推理计算。
MTT S4000 支持 FP64、FP32、TF32、FP16、BF16、INT8 等主流精度算力。
第三代 MUSA 软件栈
MUSA 是摩尔线程自研的元计算统一系统架构,包括指令集架构、MUSA 编程模型、驱动、运行时库、算子库、通讯库、数学库等。更为重要的是,通过摩尔线程自研的 MUSIFY 工具,可以实现 CUDA 程序平滑迁移至 MUSA。
全面支持主流图形 API
MTT S4000 支持 DirectX、Vulkan、OpenGL、OpenGL ES 等主流图形 API,可为数字孪生、云游戏、云渲染、数字内容创作等场景提供全平台通用图形渲染能力支持。还可配合大模型推理能力,实现 AIGC 等多模态业务场景的一站式解决方案。
查看支持的模型列表






