 EN
EN


基于“ 平湖 ”架构
定义生成式 AI 时代的国产旗舰算力
MTT S5000 是一款面向生成式 AI 时代,专为大模型训练、推理及高性能计算而生的全功能 GPU 智算卡。其核心搭载了摩尔线程全新一代 PH100 芯片,凭借先进的“平湖”架构,提供从 FP8 到 FP64 的全精度算力支持。PH100 芯片已首批通过中国信息安全测评中心的安全可靠测评(2026年第2号)。
MTT S5000 依托第四代 MUSA 全栈平台打破生态壁垒,原生适配 PyTorch、Megatron-LM、vLLM 及 SGLang 等主流框架,让用户能够以“零成本”完成代码迁移。无论是构建万卡级超大规模训练集群,还是部署高并发、低延迟的在线推理服务,基于 PH100 芯片强劲性能与高安全等级的 MTT S5000 均展现出对标国际主流旗舰产品的卓越性能与稳定性,为您构建坚实、易用且自主可控的国产算力底座。
FP8 原生算力
万亿模型训练和推理的算力标准
在大模型参数持续扩张的趋势下,FP8 计算精度的支持已成为训练与推理前沿模型的核心精度标准。MTT S5000 率先实现硬件级原生 FP8 计算精度支持,在确保模型收敛的同时显著降低显存占用。针对大规模集群面临的带宽与算力瓶颈,MTT S5000 的 FP8 引擎全面支持 DeepSeek、Qwen 等前沿架构,训练性能提升超 30%,并大幅优化总体拥有成本。
面向万亿级参数大模型训练的万卡集群标杆
面对万亿参数大模型对算力规模与工程稳定性的极致挑战,MTT S5000 以前瞻性架构设计实现从单卡到万卡集群的线性性能跃升。在万卡级超大规模预训练实测中,MTT S5000 展现出卓越的精度一致性,训练效果与国际旗舰产品高度对齐。凭借突破性的算力利用率(MFU)表现,确保大规模训练任务的确定性交付与极致性能。
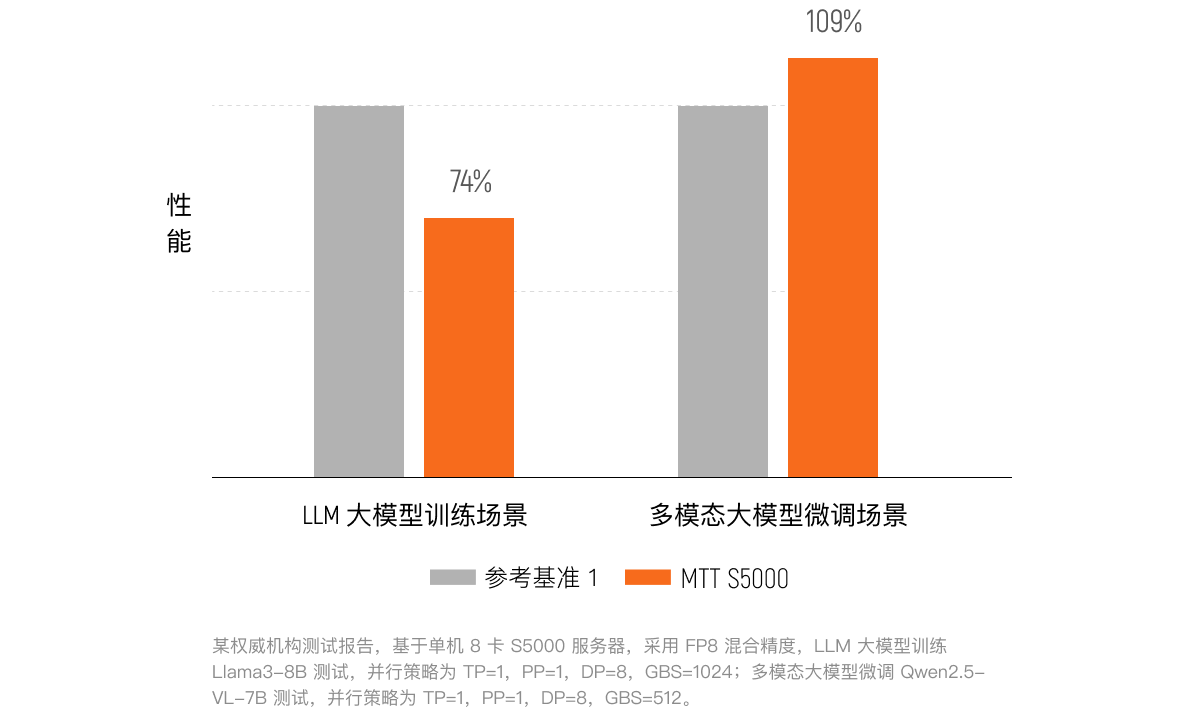
综合训练性能
多模态微调超越:在多模态大模型微调任务中,实测性能表现优于国际旗舰产品① 。

大规模集群高效率
DeepSeek-236B 训练:模型算力利用率 (MFU) 超过 40%。
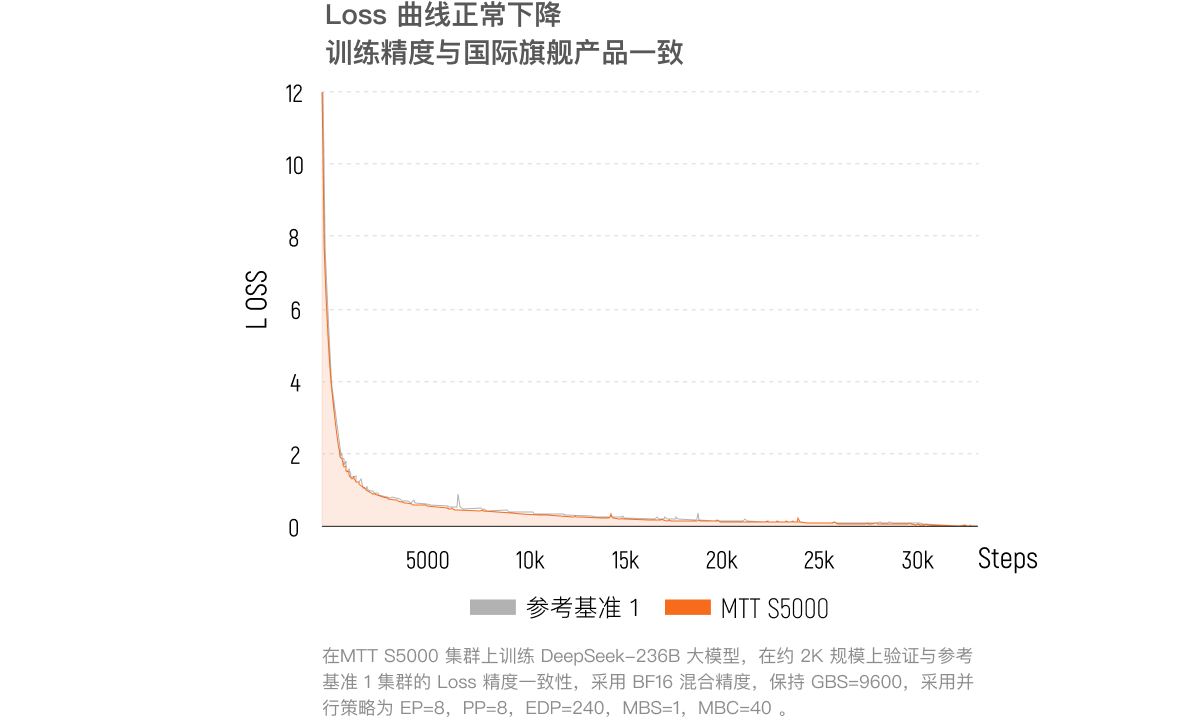
万卡集群高精度
下游表现更优:在同等数据量下,下游任务评测得分优于国际旗舰产品①,验证了万卡集群的高精度。
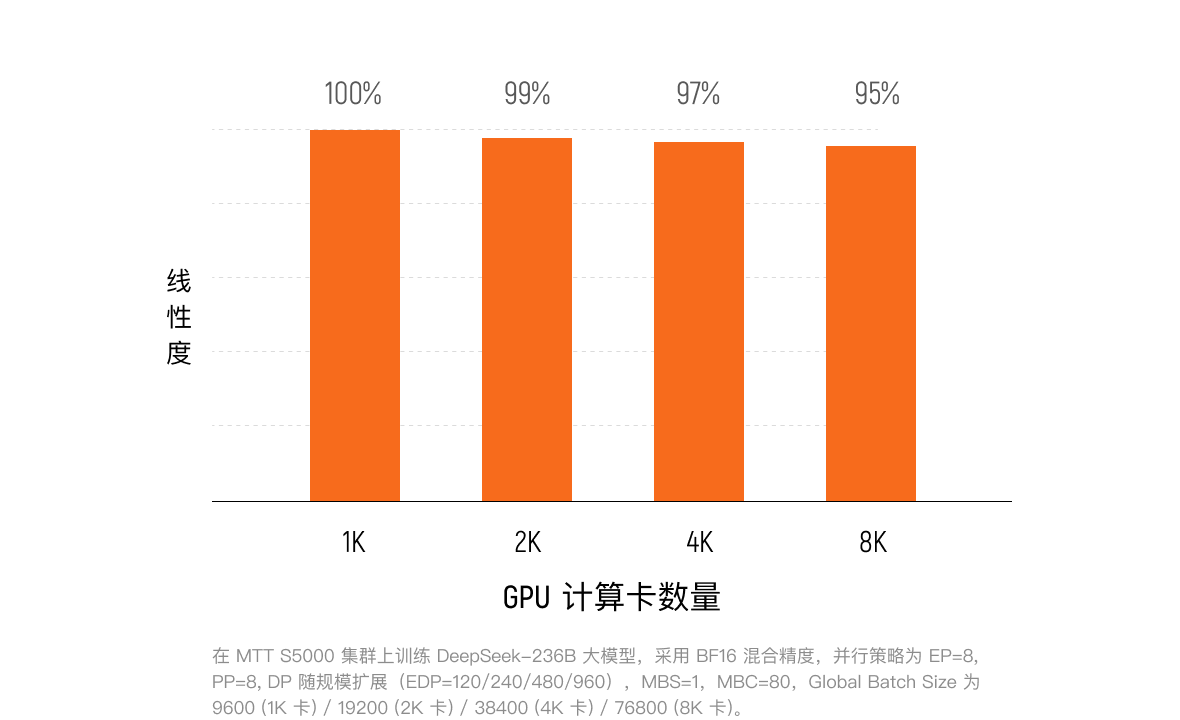
集群扩展

可靠、可用和可维护
MTT S5000 从芯片级到系统级全面构建 RAS 体系,支持故障感知、上报与错误隔离,可快速定位并替换故障节点、慢节点及静默数据损坏节点;主动检测与修复,长期守护集群健康,确保性能稳定与结果正确。依托芯片级到系统级的 RAS 能力,MTT S5000 将万卡集群的训练成功率提升超 30%。
瞬时响应与极速交互
打造大模型推理的极致用户体验
MTT S5000 致力于打破算力与交互之间的屏障,通过软硬一体化深度协同,为 AI 应用提供近乎零延迟的响应体验。针对大语言模型推理场景,MTT S5000 进行了全栈式优化,通过集成 SGLang、vLLM 等高性能推理软件栈,充分发挥硬件架构在长序列处理与高频解码中的算力优势。
在长文本上下文理解任务中,MTT S5000 显著提升了预填充(Prefill)阶段效率,有效降低首 Token 延迟,确保复杂指令的即时响应。在内容生成阶段,通过深度优化解码(Decode)吞吐性能,实现了出众的文本输出速率。这一推理效能不仅满足用户对极速交互的需求,更在高并发访问场景下,为企业提供了更优的算力能效比与稳定的服务保障。
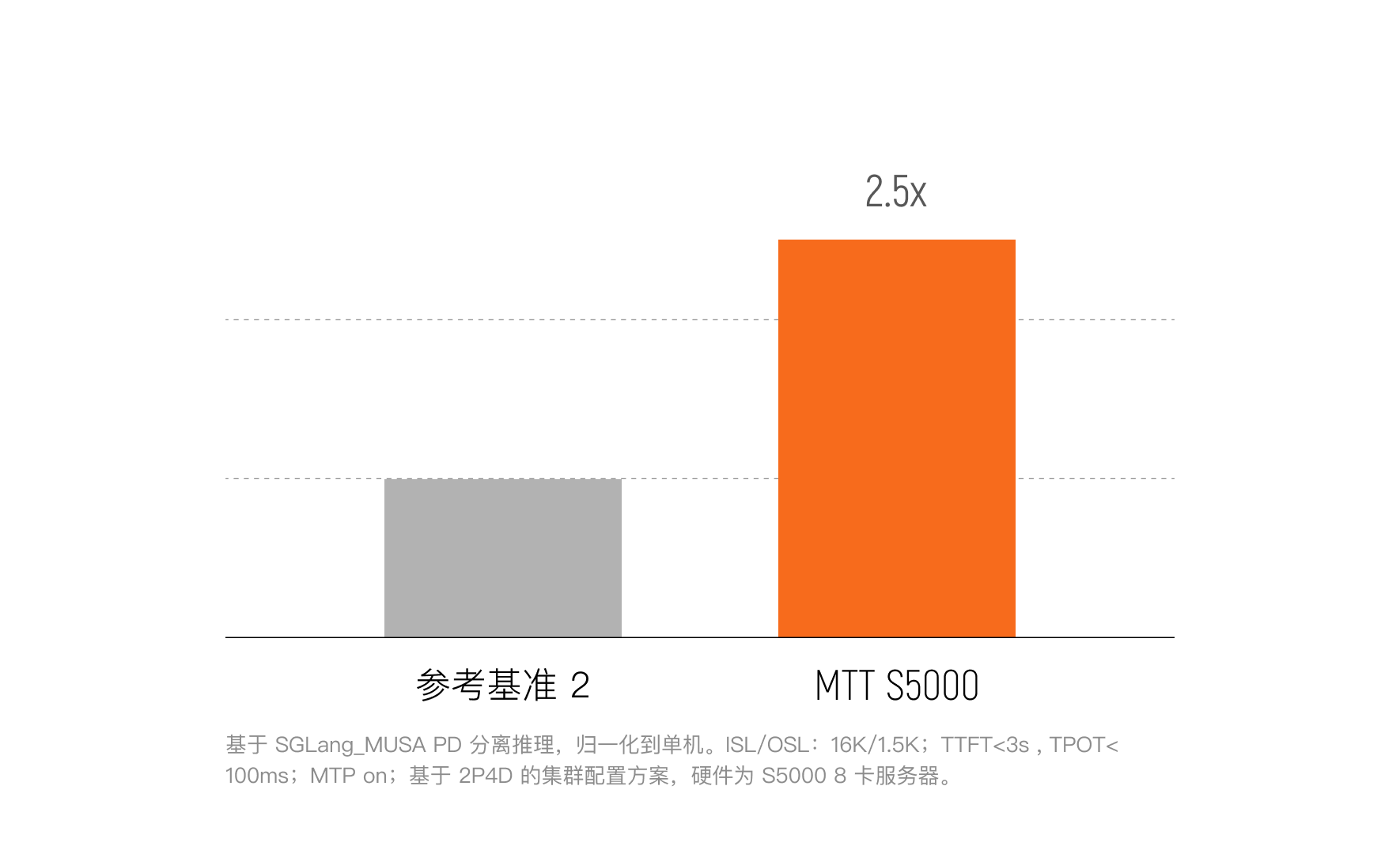
Prefill 性能飞跃
实现长文本瞬时首字响应
在 16k 长序列输入测试中,MTT S5000 单卡 Prefill 吞吐量是国际旗舰产品② 的 2.5 倍。这意味着在处理长文本 Prompt 时,国产算力具备更快的上下文理解速度。
以极速交互表现赋能智能体与 AI 编程
在智能体交互(Agentic AI)与 AI 编程辅助(AI Coding)等对推理时效性要求极高的场景中,MTT S5000 展现了卓越的推理效能。针对 Agent 间的高频通讯与复杂代码块的瞬时生成需求,MTT S5000 在 DeepSeek 等前沿模型的推理实测中,实现了远超行业基准的 Token 生成速率。
这种近乎“零感延迟”的输出能力确保了多智能体协作(Agent-to-Agent)时指令流转和反馈的实时性,大幅提升生产力上限,为下一代自主化、协作化 AI 应用奠定坚实的性能底座。
≥4000Tokens/s
单卡 Prefill 吞吐
ISL 为 4K,mean TTFT<=4s;MTP on;方案为 PD 分离推理,基于 2P4D 的集群配置方案,硬件为 6 台 S5000 8 卡服务器,软件为硅基流动的高性能推理引擎和摩尔线程底层软件栈,测试基于原生 FP8 计算精度,测试条件和高负载生产环境保持一致。
≥1000Tokens/s
单卡 Decode 吞吐
ISL/OSL 为 1K/2K;mean TPOT<=100ms;MTP on;方案为 PD 分离推理,基于 2P4D 的集群配置方案,硬件为 6 台 S5000 8 卡服务器,软件为硅基流动的高性能推理引擎和摩尔线程底层软件栈,测试基于原生 FP8 计算精度,测试条件和高负载生产环境保持一致。
加速多模态前沿模型训练与推理
高效训练多模态大模型 加速视频生成迭代创新
MTT S5000 凭借卓越的张量计算能力与高度优化的并行框架,在视频与图像生成领域展现出顶尖的工程实效。基于 FSDP2 框架,MTT S5000 已率先完成 Wan2.1 视频生成全模型训练验证。
在 2 节点 16 卡配置下,MTT S5000 实现了高达 61.83 samples/s 的训练吞吐量,模型算力利用率(MFU)达到 51%。其生成效果在视频逻辑、画质细腻度及动态一致性上均精准对齐行业基准。从高效预训练到高并发推理,MTT S5000 为视频生成大模型的高效进化提供全栈式算力支撑。
Drone view of waves crashing against the rugged cliffs along Big Sur's garay point beach.The crashing blue waters create white-tipped waves,while the golden light of the setting sun illuminates the rocky shore. A small island with a lighthouse sits in the distance, and green shrubbery covers the cliffs edge. The steep drop from the road down to the beach is adramatic feat, with the cliff's edges jutting out over the sea. This is a view that captures the raw beauty of the coast and the rugged landscape of the Pacific Coast Highway.
文生视频高效推理
MTT S5000 针对文生视频模型进行了深度优化。基于原生 FP8 硬件加速能力,在大幅提升推理速度的同时,确保“生成内容精度无损”,为企业提供极具竞争力的视频生成推理解决方案。

强劲效能表现
单机性能达到国际旗舰产品① 的 64%-79%,兼顾高性能输出与高投入产出比(ROI),提供极具竞争力的算力底座。

原生 FP8 无损推理
依托硬件原生 FP8 精度推理,在大幅提升推理吞吐效率的同时,确保视频生成画质无损 ,实现速度与质量的完美平衡。

灵活弹性部署
完美适配主流视频模型,支持从单机到大规模集群的无缝扩展,灵活满足不同规模的业务落地需求。
原生 FP64 双精度算力
驱动科学计算与 AI4S 跨代演进
MTT S5000 凭借强大的原生 FP64 双精度计算能力,成为驱动科学计算和 AI4S 的强劲引擎。通过与国家级实验室的深度合作与调优,在关键科学计算领域实现性能飞跃。

全精度硬件支撑
具备从 FP8 到 FP64 的全精度处理能力,确保科学模拟中极高的数据精度需求,为精密计算提供可靠保障,也为超智融合提供算力基础。

分子动力学突破
在 SPONGE 模拟引擎中,MTT S5000 凭借高效的并行计算架构,性能达到国际旗舰产品③ 的 1.7 倍。

生物制药效率飙升
在分子对接工具 DSDP 的实测中,MTT S5000 的计算效能展现出压倒性优势,性能达到国际旗舰产品③ 的 8.1 倍。

广泛的国产算力生态
快速适配主流科学计算软件栈,为材料科学、生物工程、气象预报等领域提供高效、自主的底层算力底座。
高性能多媒体处理
作为一款全功能 GPU,MTT S5000 集成了高性能的多媒体编解码引擎,能够为“云端多媒体 + AI”融合场景提供强大的多媒体处理能力。视频解码格式支持丰富,硬件原生支持 H264、H265、VP9、AV1、AVS2、AVS+、VP8 等格式。 视频编码硬件原生支持 H264、H265、AV1 等格式。
160路
高并发解码
最高支持 160 路 1080P30 视频解码能力
满足高密度视频分析需求
40路
高清解码
最高支持 40 路 4K30 视频解码能力
满足高清视频分析需求
硬件级安全防护
MTT S5000 采用硬件级可信执行环境 ,构建了从底层硬件到应用层的全栈安全防线,为敏感数据处理与模型资产提供严密保护。

硬件信任根 (HRoT)
内置硬件信任根,支持安全启动、固件安全更新与保护,确保设备从上电到运行的全生命周期安全可控。

支持机密计算
通过硬件隔离技术,在数据处理过程中提供加密保护,有效防止未授权访问,助力金融、医疗等高敏行业实现数据安全流通。

国密算法原生支持
全面支持国密算法,满足信创合规与高安全等级业务的加密需求。
软件“零成本”迁移
得益于 MUSA 架构对 CUDA 语法的高度兼容性,开发者可直接复用现有代码与开发经验,实现软件生态的平移与“零成本”迁移。

MUSIFY 自动移植工具
摩尔线程自研 MUSIFY 工具支持自动识别与代码转换,将原本需数周的适配工作缩短至数小时,实现真正的“即插即用”。

无需重构核心代码
MUSA SDK 完整支持 Runtime API、Driver API 及主流数学库,已有 GPU 应用无需重写核心逻辑即可在 MTT S5000 上高效运行。

主流 AI 框架原生支持
深度适配 PyTorch、PaddlePaddle 等主流框架,通过 Torch-MUSA 等插件实现完整支持,保障业务快速上线。
全能算力引擎
驱动跨学科科技前沿的创新研发
MTT S5000 凭借其从 FP8 到 FP64 的全精度计算能力,以统一通用架构灵活应对高精度与混合精度的 AI+ 计算任务,广泛适用于量子科技、具身智能、世界模型、医疗影像、基因研究、工业大模型、物理仿真、分子动力学等前沿应用场景。

AI + 量子科技 量子科技

AI + 具身智能 具身智能
AI + 医疗影像分析 医疗影像
AI + 基因研究 基因研究

AI + 工业大模型 工业模型

AI + 物理仿真计算 物理仿真
AI + 分子动力学 分子动力
完善的 MUSA 软件生态,加速全场景计算创新
全栈 MUSA 软件栈,涵盖驱动、MUSA 软件开发套件(MUSA SDK)、AI 训练套件(KUAE Training Suite)与 AI 推理套件(KUAE Inference Suite),全面覆盖 AI 训练、AI 推理及科学计算等场景的软件集成与使用需求,为开发者提供端到端支持。
MUSA SDK 内置深度学习加速库、数学计算库等核心组件,高效优化矩阵运算、深度学习常用算子、集合通信、线性代数及通用数学计算等关键负载。依托 MUSA 软件栈,MTT S5000 可提供卓越的计算效率与极简的迁移体验,助力科研机构与企业在大模型训练、科学计算、图像处理等任务中,快速实现性能跃升与业务落地。
MTT S5000 产品规格
灵活的硬件选择,满足多样化部署需求

OAM 计算模组
液冷版专为高密度绿色数据中心打造,释放极致算力密度的同时,显著降低 PUE 与能耗。
风冷版适配标准通用服务器,部署灵活便捷,有效降低运维门槛与长期持有成本。

MTT MGX 8-GPU 模块化平台

MTT SGX5000 服务器
服务器在散热、供电、I/O 扩展性等方面充分优化,支持风冷和液冷两种机型,满足不同数据中心部署的需求。
可预装优化训练、推理软件栈,实现软硬件一体化交付,开箱即用。
了解更多
① 参考基准 1:稠密 FP16 算力 989 TFLOPS,显存带宽 3.35TB/s;② 参考基准 2:稠密 FP16 算力 148 TFLOPS,显存带宽 4.0TB/s;③ 参考基准 3:稠密 FP16 算力 312 TFLOPS,显存带宽 2.0TB/s。








